Table of Contents
Challenge: Personalized Age Estimation
📅 Deadline: 31.12.2025 21:59
🏦 Points: 15 (beating baseline) + 20 (leader-board)
This page outlines the course challenge on Personalized Age Estimation. This project is intended for students interested in exploring the course topics in greater depth through a practical application.
Participation is optional and does not contribute to the mandatory homework point total. However, successful completion provides a more direct and easier path to achieving a final grade of A or B.
Task Description
The challenge is to implement a model for personalized age estimation. The objective is to improve the age prediction for an individual by leveraging a reference image of the same person with a known age.
The prediction problem is defined as follows: Given face 1 of a person, its corresponding age 1, and a second image, face 2, of the same person, the task is to predict age 2.
For instance, using the first image of Zdeněk Svěrák and his known age, the task is to predict his age in the second image.


Rules
- You can only use the provided data
- The solution must finish under 15 minutes on BRUTE (The baseline runs for ~4 minutes)
- You must work independently. Discussions are encouraged, however, everyone must submit their own unique submission
Provided Resources
A template (.zip) is provided, containing the dataset and a baseline solution.
(ZIP the provided files without the dataset)
Dataset
The dataset is partitioned into `train`, `val`, and `test` sets.
- You are only permitted to use the provided data.
- You may use the data splits as you see fit (e.g., merge them for training, create a new validation split, etc.).
- The template code demonstrates the data loading procedure and structure.
- We evaluate your solutions on a hidden test set, which is roughly the size of the combined public `train`, `val`, and `test` sets.
The age distribution is consistent across the data splits, meaning performance on the public data should generalize to the hidden evaluation set.

Baseline Model and Solution
The template includes a pre-trained ResNet-50 model.
- It is provided as a JIT scripted module for efficient inference.
- The model outputs age posteriors (a probability distribution over different ages), which may be a useful feature for your solution.
- For students who wish to fine-tune the model, a weight checkpoint is available upon request. Please contact us if you require it.
The baseline script implements a simple offset-based approach:
# Calculate the prediction error on the reference image offset = true_age_1 - prediction(face1) # Adjust the target prediction using half of the calculated error final_prediction_face_2 = prediction(face2) + (offset / 2)
The objective of the challenge is to design and implement a method that improves upon this baseline.
Grading and Evaluation
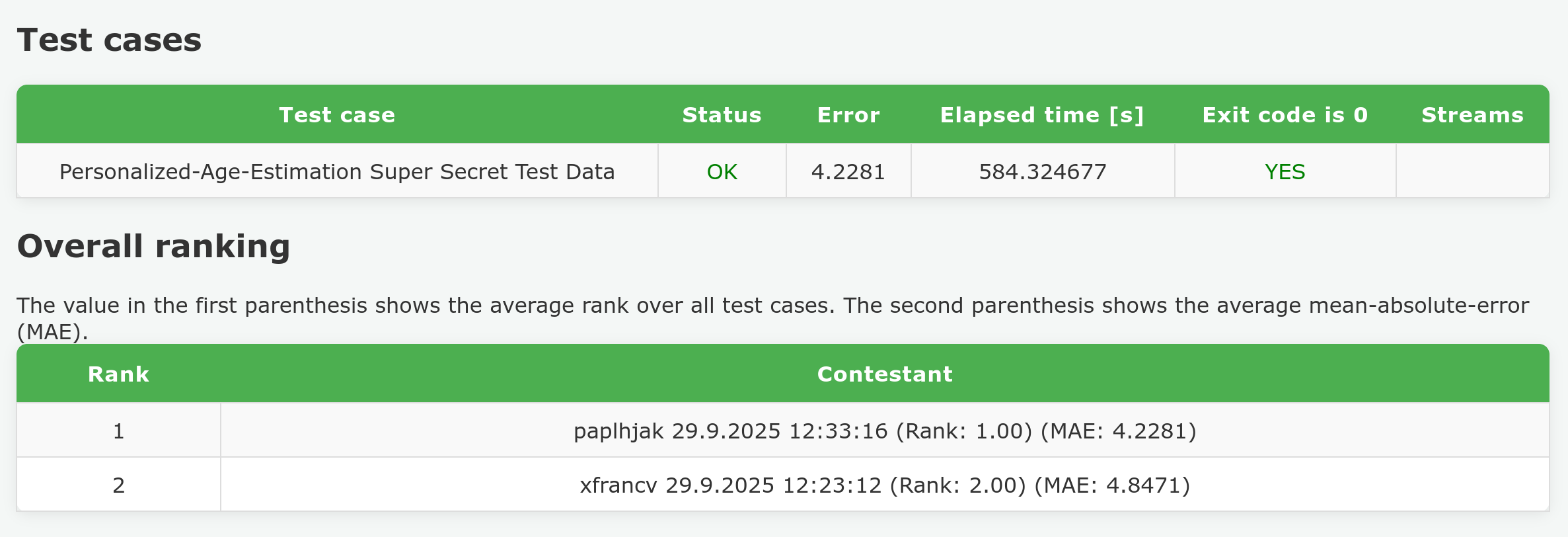
Solutions will be evaluated based on Mean Absolute Error (MAE) on a hidden test set.
- 15 points are awarded for achieving MAE of 4.5 or better. The provided baseline achieves MAE of ~4.85.
- Up to 20 additional points will be awarded to the top-performing solutions on the leaderboard.
- To be eligible for any points from the challenge, participants must submit a very short PDF that briefly explains their approach (a single paragraph is enough) along with the training code. This requirement is in place to ensure that no additional data was used during training and so that we can learn something from your solutions.
You can see the leader-board after submitting a solution and clicking the AE Result button.
Submission and Testing Procedures
Local Testing
After implementing your solution, you can test it locally using the provided public test cases:
python main.py test-cases/public/instances/test_processed.json
Submission
- Submit your completed code as a single .zip file via the BRUTE system.
- The evaluation will be performed automatically.
Environment
The evaluation is performed using Python in a Docker environment with GPU support: BRUTE PyTorch GPU Docker.
Support and Contact
For any questions or issues, please contact Jakub Paplhám at paplhjak@fel.cvut.cz. He is also available in person during the 2nd and 3rd seminars every Thursday or at the lectures.