Table of Contents
Computer Lab 10, Spam filter II
- PC lab is not taking place this week!
- Students are encouraged to follow the instructions below to program the Spam Filter I. These instructions are a simplified version of the instructions Spam filter - step 1, Spam filter - step 2 and Spam filter - step 3.
Homework
Finish the homework on files and submit it to the upload system. Deadline is tonight 23:59!
Work on the spam filter task. Submit your solution according the specifications into upload system. Deadline is Dec 6 2019!
Spam filter - steps 1-3
- Create a new PyCharm project. Call it, for example, spam_filter.
- Download traning/test data from Data, unzip the archive and place it in the root folder of the project you created in the previous step. You should now see folders “1” and “2” in your PyCharm project.
- Create a new module
utils.pyin your project. - Create a new function
def read_classification_from_file(fpath)inside theutils.pymodule.fpathis a string containing file path either to !truth.txt or !prediction.txt file. See how these files are formated in Spam filter - step 1. Implement this function so that is outputs a dictionary where keys are email filenames and values are classifications (“SPAM”/“OK”).def read_classification_from_file(fpath): """Return a dictionary with email classification :param fpath: string, path to a text file !truth.txt or !prediction.txt :return: dictionary, keys are email filenames, values are their classicifications """
- Create a new function
def write_classification_to_file(cls_dict, fpath)inside theutils.pymodule. This function takes a dictionary with email classifications and writes it to a file in a pre-defined format.cls_dictis a dictionary with email filenames and their classifications - the exact same structure as the output of theread_classification_from_file()function;fpathis a string with a filepath to a file that should be created (this will be typically !prediction.txt). This is practically an inverse function of theread_classification_from_file(). For more information see Spam filter - step 1. - Create a new module
quality.py - Write a function
def compute_confusion_matrix(truth_dict, pred_dict, pos_tag = True, neg_tag = False)inside thequality.pymodule. This function receives a dictionarytruth_dictwith a ground truth classification (emails manually labeled spam/ok) and a dictionarypred_dictwith a classification “guessed” by the spam filter. A spam filter is usually not 100% correct when predicting which emails are spam and which not. This function should, therefore, compare the spam filter estimate with the ground truth and come up with a four-number characteristics:
- TP (true positives; the cases for which the classifier predicted ‘spam’ and the emails were actually spam)
- TN (true negates; the cases for which the classifier predicted ‘not spam’ and the emails were actually real)
- FN (false negatives; the cases for which the classifier predicted ‘not spam’ but the emails were actually spam)
- FP (false positives; the cases for which the classifier predicted ‘spam’ but the emails were actually real)
This function has two extra parameters pos_tag and neg_tag. They specify how positive and negative cases in the input dictionaries are coded. Typically pos_tag = “SPAM” and neg_tag = “OK”. Output of this function is a namedtuple containing tp, tn, fn, fp. For more information and a few test cases see Spam filter - step 2.
- Write a function
quality_score(tp, tn, fp, fn)in thequality.pymodule. It receives 4 integers - tp, tn, fp, fn (described above) - on the input and it outputs a single number - prediction quality measure, defined by the following formula: $ q = \frac{TP + TN}{TP + TN + 10 \cdot FP + FN}$. Note: False positives (Real message is classified as spam) are multiplied by the factor of 10. That is, 1 FP is worth 10 FN. Keep that in mind when implementing your own spam filter. - Write a function
compute_quality_for_corpus(corpus_dir)in thequality.pymodule. This function receives a path to a directory (corpus_dir) where !truth.txt and !prediction.txt are expected. You should utilize the functions from the previous steps in order to read these two files and deduce a prediction quality measure. More information here. See the following diagram for the recommended structure: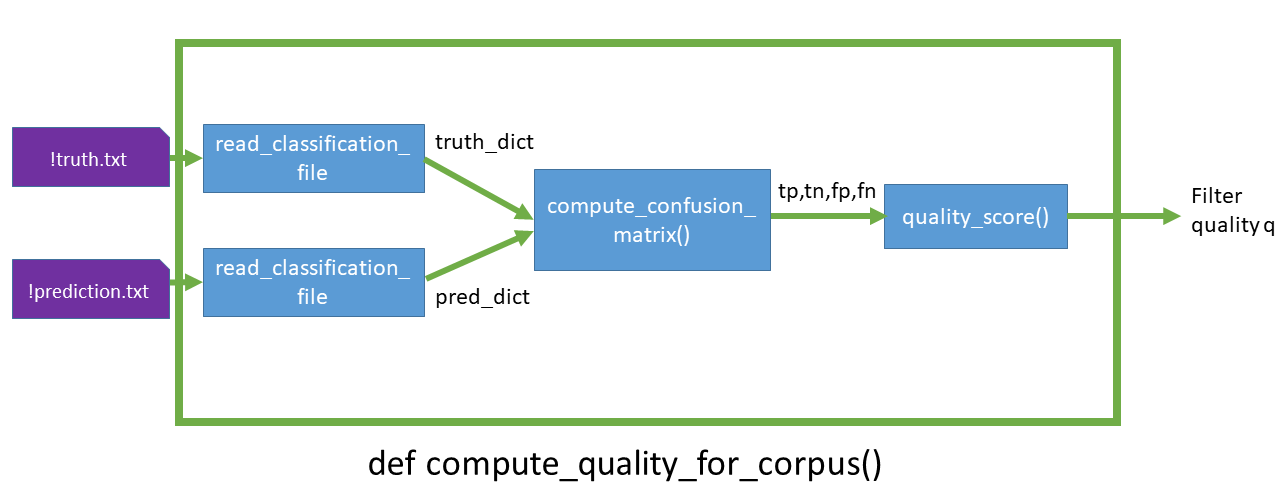
- Check specifications before uploading your solution into upload system.