TEST 01
- (0.5 b) Popište rozdíl mezi informovanými (učení s učitelem) a neinformovanými (učení bez učitele) metodami data miningu?
- (1 b) Pan Brown je majitel malé pekárny. Věří, že vůně čerstvě upečeného pečiva přiláká zákazníky do jeho obchodu, a tak zvýší jeho tržby. Jednoho dne se rozhodl provést experiment: 10 dní zaznamenával výši tržeb při otevřených oknech, a poté 10 dní při oknech zavřených. Tržby v britských librách pro jednotlivé případy jsou uvedeny v následujícím výpisu:
# tržby při otevřených oknech w_open <- c(202.0, 204.5, 207.0, 215.5, 190.8, 215.6, 208.8, 187.8, 204.1, 185.7) #tržby při zavřených oknech w_closed <- c(193.5, 192.2, 199.4, 177.6, 205.4, 200.6, 181.8, 169.2, 172.2, 192.8)Za předpokladu, že tato data jsou náhodným výběrem z normálních rozdělení se stejným rozptylem, zodpovězte postupně na tyto otázky:
- (0.2 b) Statistický test (Studentův t-test) formulujte jako test jednostranný, s alternativní hypotézou, že střední hodnota rozdělení tržeb při otevřených oknech je vyšší než při oknech zavřených.
- (0.2 b) Uveďte odhad sdruženého rozptylu.
- (0.2 b) Uveďte hodnotu testové statistiky.
- (0.2 b) Uveďte kritickou hodnotu (nebo kritický obor)
- (0.2 b) Jaký můžeme z tohoto vyvodit závěr pro navržené hypotézy?
- (Bonus, 0.2 b) Jaká je dosažená p-hodnota?
Pozn.: Veškerý postup zaznamenávejte co nejdetailněji na papír. K numerickému dosazení do vzorců a hledání kvantilů příslušných rozdělení použijte R studio.
Cvičení 2
Průzkumová analýza
- pojmy: datová matice, pozorování, příznaky (prostor příznaků), typy dat, expertní informace, rozdělení a rozsah hodnot, chybná vs. odlehlá pozorování, chybějící data
- pojmy ze statistiky: náhodná veličina (rozdělení, střední hodnota, rozptyl) vs. realizace náh. veličiny = náh. výběr (histogram, výběrový průměr, výběrový rozptyl, výběrový korelační koeficient
- Úkolem průzkumu dat je seznámit se se strukturou dat a popsat každý atribut základními statistickými údaji.
 Do svého pracovního adresáře uložte soubor iris.csv
Do svého pracovního adresáře uložte soubor iris.csv
# načtení dat
setwd('/home/user/...')
data <- read.csv("iris.csv")
Nebo využijte knihovnu datasets package, která iris data obsahuje 1111111
library(datasets) data <- irisJednoduchá průzkumová analýza
# popis dat
dim(data)
names(data)
data[1:5,]
str(data)
summary(data)
dsum <- apply(data[,1:4],2,mean)
dsum <- tapply(data$Sepal.Length, data$Species, mean)
dsum <- by(data[1:4],data$Species,function(x) {apply(x,2,mean)}) # vrací list - není moc praktické pro další manipulaci, lze převést na data frame pomocí do.call('rbind',dsum)
# pokročilou manipulaci s daty nabízí knihovna plyr
library(plyr)
dsum <- ddply(data,.(Species),function(x){apply(x[,1:4],2,mean)})
# užitečné funkce - mean, sd, median, is.na, is.nan, is.finite, ...
Grafy v R
Klasické bodové a čarové grafy
plot(data$Sepal.Length)
plot(data$Sepal.Length,type='l')
plot(data$Sepal.Length,type='b')
plot(data$Sepal.Length,data$Sepal.Width)
plot(data$Sepal.Length,data$Sepal.Width,col=data$Species)
plot(data$Sepal.Length,data$Sepal.Width,col=data$Species,pch=19)
plot(data$Sepal.Length,
data$Sepal.Width,
col=data$Species,
pch=19,
main='Edgar Anderson\'s Iris data',
xlab='Sepal Length',
ylab='Sepal Width')
# legenda
legend('topright',
legend=levels(data$Species),
pch=19,
col=1:length(levels(data$Species)))
# vykreslit body
avgSepal.Length <- tapply(data$Sepal.Length,data$Species,mean)
avgSepal.Width <- tapply(data$Sepal.Width,data$Species,mean)
points(avgSepal.Length,avgSepal.Width,pch='X',cex=2,col=4)
# vykreslit čáry
lines(lowess(data$Sepal.Length[data$Species=='setosa'],data$Sepal.Width[data$Species=='setosa']))
lines(lowess(data$Sepal.Length[data$Species=='versicolor'],data$Sepal.Width[data$Species=='versicolor']),col=2)
lines(lowess(data$Sepal.Length[data$Species=='virginica'],data$Sepal.Width[data$Species=='virginica']),col=3)
# další elementy - line(), abline(),
Varianty argumentu pch zde.
Boxplot
boxplot(data$Sepal.Length ~ data$Species)
# přídáme barvu a datové body
boxplot(data$Sepal.Width ~ data$Species , col=terrain.colors(3) )
mylevels<-levels(data$Species)
levelProportions<-summary(data$Species)/nrow(data)
for(i in 1:length(mylevels)){
thislevel<-mylevels[i]
thisvalues<-data[data$Species==thislevel, "Sepal.Width"]
# take the x-axis indices and add a jitter, proportional to the N in each level
myjitter<-jitter(rep(i, length(thisvalues)), amount=levelProportions[i]/2)
points(myjitter, thisvalues, pch=20, col=rgb(0,0,0,.2))
}
Histogram
hist(data$Sepal.Length) hist(data$Sepal.Length,100)Histogramy pro jednotlivé třídy v jednom grafu
hist(data$Sepal.Length[data$Species == 'setosa'],
50,
xlim=c(min(data$Sepal.Length),
max(data$Sepal.Length)),
col=2,
main='Edgar Anderson\'s Iris data')
hist(data$Sepal.Length[data$Species == 'versicolor'],50,col=3,add=T)
hist(data$Sepal.Length[data$Species == 'virginica'],50,col=4,add=T)
Scatter Plot Matrix
pairs(data)
Příklad 1 (boxplot)
Využijte vestavěný dataset
airquality a sestrojte boxploty teploty vzduchu v závislosti na měsíci měření. Nezapomeňte pojmenovat osy a dát grafu titulek. Dále boxploty obarvěte oranžovou barvou. Nakonec pomocí vhodné funkce (na jednom řádku) vypište mediány teplot přes všechny měsíce.
Řešení

5 6 7 8 9 66 78 84 82 76
Příklad 2 (histogram)
- Pomocí funkce
rnormvygenerujte 2 vektory o délce 4000 z normálního rozdělení o střední hodnotě 100, resp. 200 a směrodatné odchylce 30 (v obou případech). Bude se jednat o dva různé druhy rostlin, hodnoty značí jejich naměřenou výšku. - Zobrazte histogram pro každou třídu do vlastního grafu. Tyto grafy umístěte na jedné stránce vedle sebe. K tomu využijte příkaz
par(mfrow=c(1,2)). - Nyní zobrazte oba histogramy do jednoho grafu. Barevně je odlište. Aby jeden histogram nezakrýval druhý, nastavte alpha kanál, který reguluje průhlednost
rgb(r,g,b,alpha). Nezapomeňte smysluplně označit osy a nastavit legendu vpravo nahoře (názvy rostlin si vymyslete libovolně).
Řešení


Grafy pomoci knihovny GGPLOT2
library(ggplot2)
Mapování dat → vizualizace
ggplot(data, aes(x=Sepal.Length, y=Sepal.Width))+geom_point() ggplot(data, aes(x=Sepal.Length, y=Sepal.Width))+geom_point()+geom_line() ggplot(data, aes(x=Sepal.Length, y=Sepal.Width))+geom_point(aes(color=Species))+geom_line() ggplot(data, aes(x=Sepal.Length, y=Sepal.Width))+geom_point()+geom_line(aes(color=Species)) ggplot(data, aes(x=Sepal.Length, y=Sepal.Width, color=Species))+geom_point()+geom_line()
Příklady grafů
ggplot(data, aes(x=Species, y=Petal.Width))+geom_boxplot() ggplot(data, aes(x=Sepal.Length))+geom_histogram() ggplot(data, aes(x=Sepal.Length))+geom_histogram(binwidth=0.1) ggplot(data, aes(x=Sepal.Length))+geom_histogram(binwidth=0.1, aes(colour=Species)) ggplot(data, aes(x=Sepal.Length))+geom_histogram(binwidth=0.1, aes(fill=Species)) ggplot(data, aes(x=Sepal.Length))+geom_histogram(binwidth=0.1, alpha=0.4, aes(fill=Species)) ggplot(data, aes(x=Sepal.Length))+geom_histogram(binwidth=0.1, position="identity", alpha=0.4, aes(fill=Species))
Příklad 3 (Barevné boxploty s ggplot2)
- Použijte dataset
mpgz R a zobrazte boxplot proměnnéhwy(highway miles per gallow) v závislosti na druhu auta. Barvu nastavte na červenou, výplň na oranžovou a alpha kanál na hodnotu 0.2.
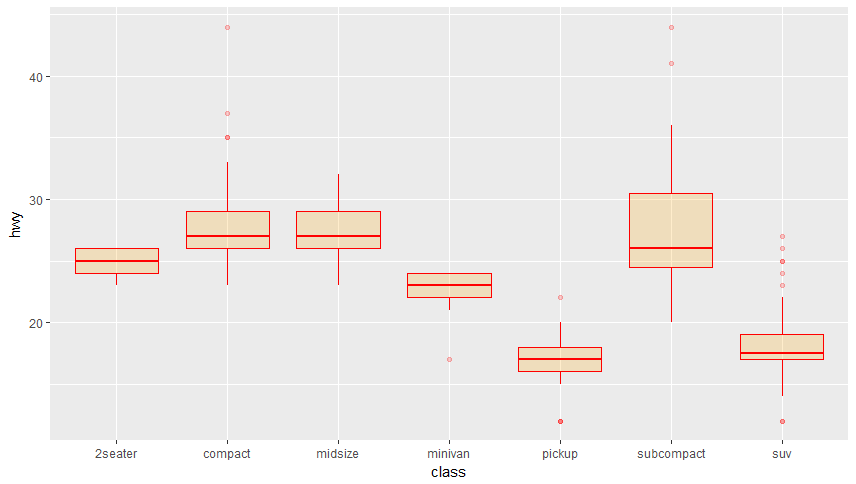
- Nyní místo oranžové obarvěte jednotlivé boxploty podle třídy (aes:
fill=class) a odeberte legendu+ theme(legend.position=“none”).
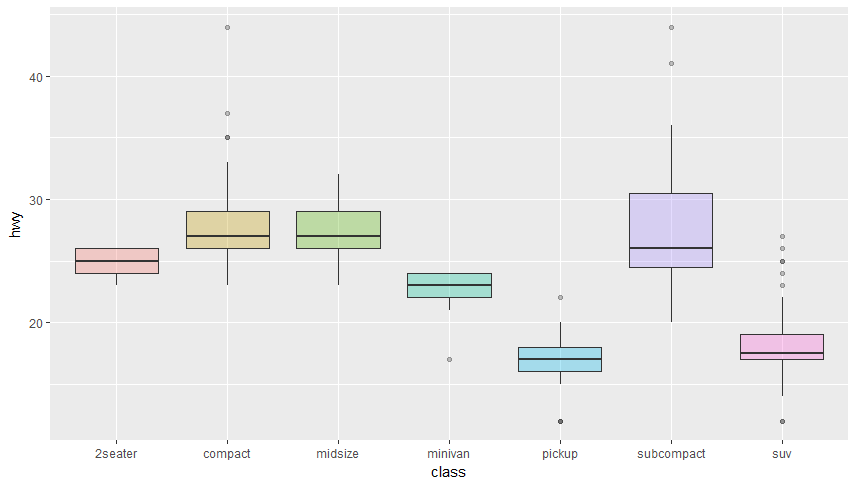
- Barevnou škálu si lze i zvolit. Vyberte si jednu z
RColorBrewer::display.brewer.all()a obarvěte grafy pomocíscale_fill_brewer(palette=“BuPu”).
Příklad 4 (chybové úsečky)
Při prezentování dat formou sloupcových grafů (a nejenom u nich), které vznikají jako agregace naměřených hodnot - např. průměrováním jednotlivých měření - je nezbytné kromě dané hodnoty zobrazit, jak přesné dané měření bylo. Často se k tomu používají tzv. chybové úsečky. Ty mohou zobrazovat kupříkladu směrodatnou odchylku.
- Nejprve si vygenerujeme dummy data. Vytvořte data frame s atributem
name = letters[1:5](co vypíše samotnéletters?),values(pomocí funkcesample()vyberte z řady4:15pět náhodných čísel bez opakování) asd = c(1, 0.2, 3, 2, 4). - Pomocí
+geom_bar()zobrazte sloupcový graf hodnotvaluespřes jednotlivá jménaname. Výplň nastavte naskyblue. (Dále nastavtestat=“identity”, jinak ggplot automaticky vykresluje četnost měření v jednotlivých skupinách místo skutečných hodnot.) - Následně pomocí
+geom_errorbar()vykreslete chybové úsečky v rozmezí +- sd od naměřené hodnoty. Barvu nastavte na oranžovou.
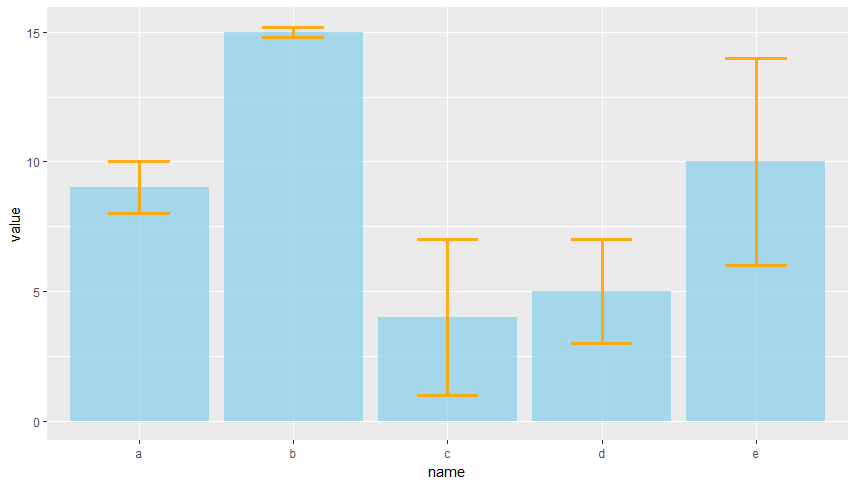
Úkoly
Použijte data "ADULT" z UCI Machine Learning Repository uložená v souboru adult.csv
- Kolik atributů data obsahují?
- Obsahují data chybějící hodnoty?
- Nakreslete histogram pro atribut workclass. Co vyjadřuje hodnota “?” tohoto atributu?
- Jaká hodnota je dominantní u atributu hours.per.week?
- Do kolika tříd máme data klasifikovat?
R script pro cvičení
bude doplněn po cvičení